Catastrophic Frequencies
Brief History of the Method
Early machine-assisted content analysis was hampered by the high costs of processing power and data storage. In 1976, DeWeese published two “technological feasibility studies of computer analysis of media content” which concluded that “a large-scale project would cost $3 million per billion words” or about $0.30/word (West, p. 19). DeWeese further found that document scanners capable of optical character recognition (OCR) cost upwards of $1.3 million (ibid.). In the late 1960s and early 1970s, mainframe time cost around $75 an hour (Stewart 2007).
Advances in computer technology, mass commercialization of personal computers and the development of “online information services that provide the full text of documents in digital form, make computer-assisted content analysis more accessible and practical now than ever before.” (West, p. 15) While consumer-grade OCR technologies are now available for less than $300 (Berline 2008), information services like LexisNexis and Canadian Newsstand have made OCR largely unnecessary for most newspaper content analysis projects. The post-millennial proliferation of UNIX-clone operating systems (e.g. Linux, FreeBSD and MacOS X) has made it possible to run mainframe applications on laptops and thus lowered the barriers to the use of powerful Unix shells.
These technological developments have, as with machine translation, lent support to post-Structuralism linguistic criticism of machine-assisted content analysis: computers still do not understand human language. Computers cannot differentiate homographs, process unrecognized phrases or symbols, parse metaphors, or make judgments or interpretations unless specifically programmed to do so (West, p.15). Many efforts have been made to overcome these limitations and lexicological software like The General Inquirer (Stone, 1966), which relies on pre-coded dictionaries to score and compare texts, have made substantial progress (Buvac, n.d.) and enjoy continued application (Lim 2008; Hall 2005).
Ironically, the acceleration of communication (and communication as entertainment) facilitated by “consumer mainframes” and global information networks has widened one of the holes in pre-coded dictionaries. Communities and world events coin new phrases, describe new symbols and invent new myths at an accelerated rate, so that phrases like “World Trade Center” may be included in a lexical database like WordNet (Miller et al., 2009) without weight for the emotion the words now evoke, and slang like “jumped the shark”1 or “epic fail”2 may be omitted entirely, at least until the next version is released.
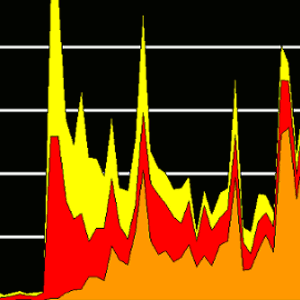
In examining the word frequencies of several catastrophes, this paper explores one possible avenue open to identifying a specific class of myths created by contemporary events: sudden calamities, or “catastrophes”. Some of the catastrophes examined have indisputably entered the realm of myth (if not mythology), and others probably never came close. While there has been a great deal of innovation in the field of infographics in recent years (e.g. Appendix C), this study limits the illustration of frequency to single and multi-variable longitudinal line and area graphs.